初心者さん向けの「いきなりPDF」の使い方 第4回
PDFの抽出 初心者入門編4回
pdfファイルから、テキストや画像を抽出します
(PDFからテキストを抽出 簡単にPDFをテキストにする方法)
PDF内のテキストや画像を抽出するには、pdfソフトを使用したほうが、簡単に取り出せます
仕事上で、状況によっては、pdfファイルから、テキストや画像を取り出したい場合は、
このPDFの抽出機能が非常に役に立ちます
pdf抽出のやり方
■pdf抽出の準備として
1)
まずは、説明するために、例として、
下図のような、『会社挨拶_0001.pdf』ファイルを用意しました
※このファイルは、説明するために、いきなりPDFで作成したものです
2)
このファイルの中身を表示してみます、下図画像です
前回まで、使用した挨拶ファイルpdfに、写真を追加して、
それを新たに、『会社挨拶_0001.pdf』
※ここで使用した、素材写真はPixabayより著作権フリーを使用してます

3)
いきなりPDFを起動して、右から2番目の「抽出」をクリックします、赤矢印
※この画面では、スタート画面のアイコンが5つあります
最上位版を使用しているので、この5個の画面になります
いきなりPDF/COMPLETE Edition Ver.5

4)
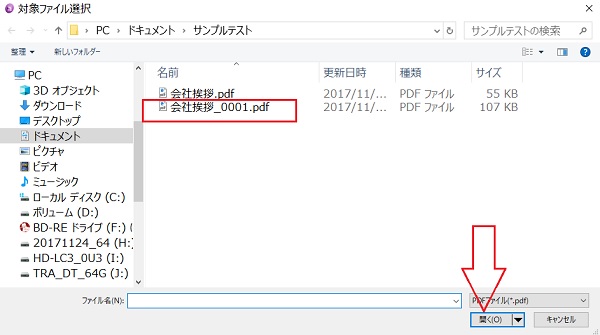
クリックすると、すぐに自動で、エクスプローラ画面が表示されますので、下図
その画面から、必要なpdfファイルをを選択します、赤枠
さらに、そのまま、「開く」をクリックします、赤矢印
※※※補足
この例では、自動で、「ドキュメント>サンプルテスト」の場所が開いています
場所は変更できるので、必要なら、その開いた画面から、選択しなおします
5)
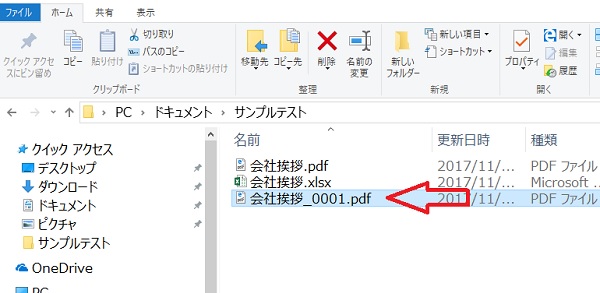
すると、pdfファイルが解析されて、テキストと画像に分かれて、抽出されます
●初心者さんに少し解説します
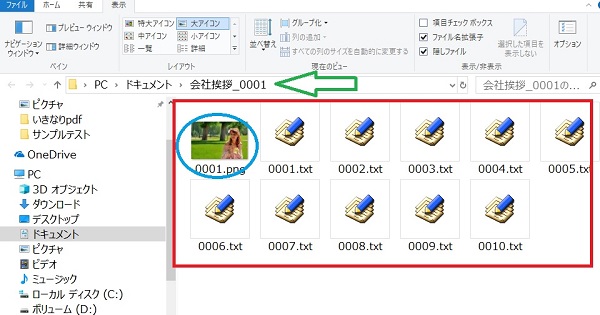
まず、自動でファルダ名が作成されています、緑矢印
これは、『会社挨拶_0001.pdf』から、ソフトが判断して、
【会社挨拶_0001】のフォルダ名を作成してます
●そのフォルダの中に、全ての、テキストと画像を分けて取り出しいます、赤枠、青丸
6)
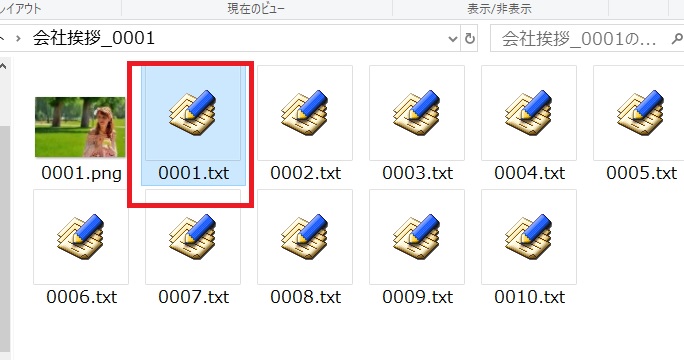
では、実際に、pdfから抽出されたテキストを確認してみます
ここでは、「0001.txt」を開いてみます
※画像は、もうみえてるので、確認する必要はないので
7)
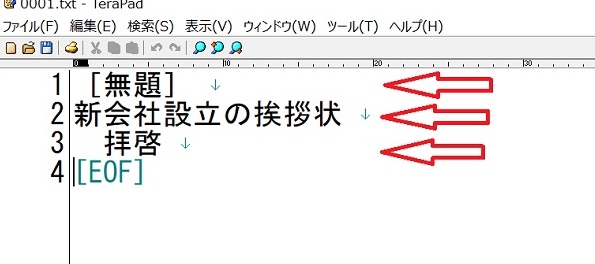
pdfから抽出された、「0001.txt」を開いた画面です
元のpdfファイルの文書と比べてみるとわかると思います
1行単位で、テキストとして、抽出されてます
8)
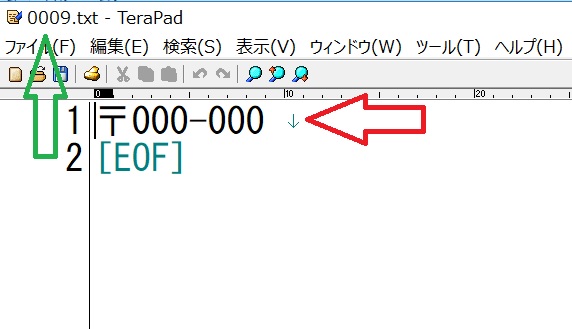
ついでに、もう1こ確認してみます、
こちらは、「0009.txt」を開いた画面です、
これも、元のpdfファイルと見比べるとよくわかると思います
郵便番号の1行部分が、テキストとして、抽出されてます
このように、いきなりPDFを使用すれば、簡単に、pdfから、画像と文字が抽出できます
あとは、テキストと画像の状態なので、あらゆるソフトで、使用でるので便利です
いきなりPDF/COMPLETE Edition Ver.5